
The Impact of Advertising Campaign Structure on Google Ads Performance
Google Introduces New Measurement Tools for YouTube Brand Campaigns

Risk Mitigation in Implementing High-Impact Technical SEO Changes: From Audit to Implementation

8 minutes
Images are no longer perceived by search engines and AI systems as a secondary content element. Today, they are analyzed in the same way as language: through OCR, visual context, and pixel-level quality. These factors determine how artificial intelligence interprets content and whether it will be used in answers, recommendations, or generative search.
Over the past decade, image SEO has primarily focused on technical hygiene:
These practices still remain foundational for a healthy website. However, the emergence of large multimodal models — such as ChatGPT or Gemini — has created new opportunities and, at the same time, new challenges.
Multimodal search unifies different types of content into a shared vector space.
Effectively, we are no longer optimizing only for the user — we are optimizing for the “machine gaze.”
Generative search makes most content machine-readable: media is broken into semantic chunks, and text from images is extracted through optical character recognition (OCR).
Images must be legible for the “machine eye.”
If AI cannot accurately read text on a product package due to low contrast or begins to “hallucinate” details because of poor resolution, this becomes a serious SEO issue, not just a design concern.
This article analyzes how the machine gaze works and shifts the focus from page load speed to machine readability.
Before optimizing content for AI comprehension, it is essential to consider a basic filter — performance.
Images are a double-edged sword.
They drive engagement but often become the main cause of:
Today, the standard of “good enough” goes beyond just WebP.
But once the image loads, the real work begins.
For large language models (LLMs), images, audio, and video are sources of structured data.
They use a process called visual tokenization: the image is divided into a grid of patches (visual tokens), and raw pixels are converted into a sequence of vectors.
Thanks to the unified model, AI can process a phrase such as
“image [image token] on a table”
as a single coherent sentence.
A key role in this process is played by OCR — it extracts text directly from the visual content.
Here, quality becomes a ranking factor.
If an image is heavily compressed and contains lossy artifacts, the visual tokens become “noisy.” Low resolution can cause the model to misinterpret these tokens.
The result is hallucinations: AI confidently describes objects or text that do not exist, simply because the “visual words” were unclear.
For large language models, alt text acquires a new function — grounding.
It acts as a semantic signpost, forcing the model to resolve ambiguous visual tokens and confirm its interpretation of the image.
As Zhang, Zhu, and Tambe note:
“By inserting text tokens near relevant visual patches, we create semantic signposts that reveal true cross-modal attention scores and guide the model.”
Practical tip:
By describing the physical characteristics of the image — lighting, composition, element placement, and text on the object — you effectively provide high-quality training data. This helps the “machine eye” correlate visual tokens with text tokens.
Search agents like Google Lens or Gemini actively use OCR to read:
As a result, they can answer complex user queries.
Consequently, image SEO extends beyond the website and applies to physical packaging.
Current regulatory requirements — FDA 21 CFR 101.2 and EU 1169/2011 — allow minimum font sizes of 4.5–6 pt or 0.9 mm for compact packaging.
“In the case of packaging or containers, the largest surface of which has an area of less than 80 cm², the x-height of the font element must be at least 0.9 mm.”
This satisfies the human eye but not the machine gaze.
The minimum pixel height for OCR-readable text should be at least 30 pixels.
Contrast is also critical: the difference should reach 40 grayscale values.
Decorative and stylized fonts pose a separate risk. OCR systems can easily confuse:
Additional challenges arise from glossy surfaces. They reflect light, creating glare that partially or fully obscures text.
Packaging should be treated as a machine readability feature, not just a branding element.
If AI cannot read a photo of the packaging due to glare or script fonts, it may fabricate information or, worse, exclude the product entirely from results.
Originality is often perceived as a subjective creative trait. However, in the context of AI, it can be measured as a concrete signal.
Original images act as canonical markers.
The Google Cloud Vision API, particularly the WebDetection feature, returns lists of:
fullMatchingImages — exact image duplicates found online;pagesWithMatchingImages — pages where they appear.If your URL has the earliest index date for a unique set of visual tokens (e.g., a specific product angle), Google credits your site as the source of that visual signal.
This directly boosts the experience metric, which increasingly affects visibility in next-generation search.
AI identifies every object in an image and analyzes their relationships to infer insights about the brand, price segment, and target audience.
For this reason, product adjacency in the frame becomes a ranking factor.
To evaluate this signal, you need to audit your visual entities.
For testing, you can use tools such as Google Vision API.
For a systematic audit of your entire media library, you need to pull the raw JSON using the OBJECT_LOCALIZATION feature.
The API returns object labels, for example:
“watch”, “plastic bag”, “disposable cup”.
Google provides an example where the API identifies objects in the image and returns data like:
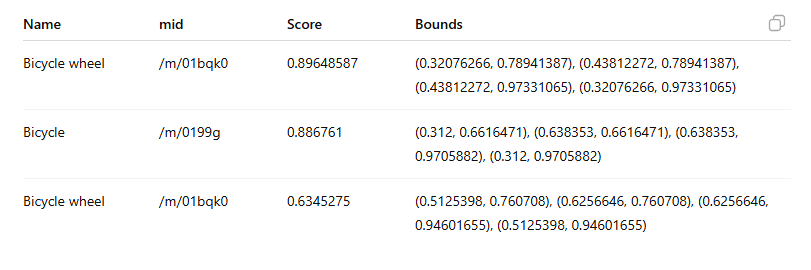
Important: The mid field contains a machine-generated identifier (MID) corresponding to an entity in the Google Knowledge Graph.
The API does not know whether this visual context is “good” or “bad.”
You do.
Therefore, the key task is to check whether the visual neighbors of the product tell the same story as its price.
By photographing a blue leather watch band next to a vintage brass compass and a warm wood-textured surface, the Lord Leathercraft brand creates a clear semantic signal: heritage and exploration.
The co-occurrence of analog mechanisms, aged metal, and tactile suede conveys a persona of timeless adventure and old-world sophistication.
However, photographing the same watch next to a neon energy drink and a plastic digital stopwatch shifts the narrative through dissonance.
The visual context now signals mass-market utility, diluting the perceived value of the product entity.
Beyond objects, these models are increasingly capable of reading emotional states.
APIs such as Google Cloud Vision can quantitatively assess emotional attributes by assigning likelihood scores to emotions such as joy, sorrow, and surprise, as detected in human faces.
This creates a new optimization vector: emotional alignment.
If you are selling fun summer outfits but the models in the photos appear moody or neutral — a common approach in high-fashion photography — AI may deprioritize the image for that query because the visual mood conflicts with search intent.
For a quick check without writing code, you can use the live drag-and-drop demo of Google Cloud Vision to review the four primary emotions:
For positive intents, such as “happy family dinner,” the joy attribute should be VERY_LIKELY.
If it reads POSSIBLE or UNLIKELY, the signal is too weak for the machine to confidently index the image as “happy.”
For a more systematic analysis:
faceAnnotations object by sending a FACE_DETECTION feature request.likelihood fields.The API returns these values as fixed categories (enums).
Example directly from official documentation:
The API evaluates emotions on a fixed scale.
The optimization goal is to move primary images from POSSIBLE to LIKELY or VERY_LIKELY for the target emotion.
Interpretation scale:
Optimizing emotional resonance is impossible if the machine can barely see the face.
If detectionConfidence is below 0.60, AI struggles to identify the face. Any emotion readings tied to that face are statistically unreliable noise.
Recommended thresholds:
Although Google documentation does not provide explicit guidance on these thresholds, and Microsoft offers limited access to Azure AI Face, Amazon Rekognition documentation notes:
“A lower threshold (e.g., 80%) might suffice for identifying family members in photos.”
Visual assets should be handled with the same editorial rigor and strategic intent as primary content. The semantic gap between image and text is disappearing.
Images are processed as part of the language sequence. The quality, clarity, and semantic accuracy of pixels themselves now matter as much as the keywords on the page.
Read this article in Ukrainian.
Say hello to us!
A leading global agency in Clutch's top-15, we've been mastering the digital space since 2004. With 9000+ projects delivered in 65 countries, our expertise is unparalleled.
Let's conquer challenges together!
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/
performance_marketing_engineers/

